
Real-Time Transaction Monitoring Pipeline
A full-stack real-time and batch data pipeline simulating fintech payment transaction monitoring.
This project simulates a fintech payment platform by building a real-time transaction monitoring pipeline.
It integrates streaming, batch processing, data modeling, and BI dashboards into one cohesive architecture — a skillset directly applicable to solving real-world problems.
💡 Project Overview
Financial institutions process millions of transactions per day. To ensure fraud detection, revenue tracking, and customer analytics, data pipelines must combine real-time monitoring with batch aggregations.
In this project, I designed and built a production-style end-to-end data pipeline that demonstrates:
- Streaming ingestion and fraud detection with Kafka + Spark Structured Streaming
- Batch modeling and aggregations with dbt
- Orchestration with Airflow
- Data quality validation using dbt tests
- Business dashboards powered by Metabase
🔧 Tech Stack
- Streaming Ingestion: Kafka
- Stream Processing: Spark Structured Streaming
- Data Storage: Postgres (warehouse schema with fact/dim tables)
- Data Modeling: dbt (transformations, aggregations, star schema)
- Orchestration: Apache Airflow
- Visualization: Metabase
- Containerization: Docker Compose
- Programming Language: Python
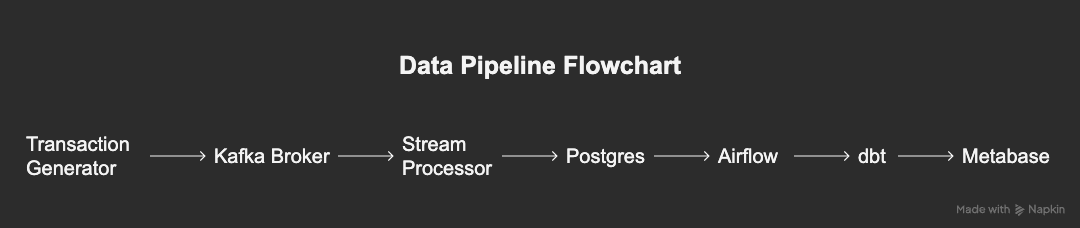
🏗️ Architecture Summary
Flow of Data:
- Transaction Generator (Kafka Producer) → Simulates live card/e-commerce transactions
- Kafka Broker → Streams transactions in real time
- Spark Structured Streaming → Consumes, validates, applies fraud detection logic
- Postgres → Stores fact and dimension data for analytics
- dbt → Transforms and aggregates into business models
- Airflow → Orchestrates dbt runs and batch jobs
- Metabase → Dashboards for fraud monitoring and KPIs
📊 Data Model
- Fact Table:
fact_transaction- Transaction-level events with fraud flags, geolocation, payment metadata
- Dimension Tables:
dim_customer,dim_merchant- Customer and merchant attributes for analytics
- Batch Models (dbt):
- Daily revenue summary
- Customer KPIs (avg spend, fraud ratio)
- Merchant analytics (sales, fraud by category/location)
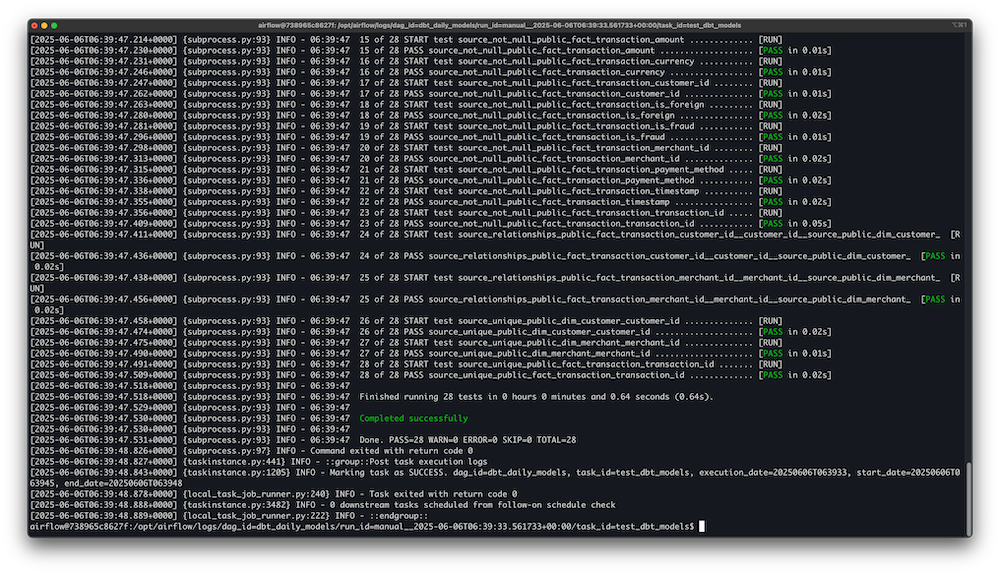
✅ Data Quality Controls
- dbt tests enforce production-grade reliability:
- Unique keys on surrogate primary keys
- Not-null constraints on business-critical fields
- Referential integrity between fact and dimension tables
- Accepted value checks for categorical fields
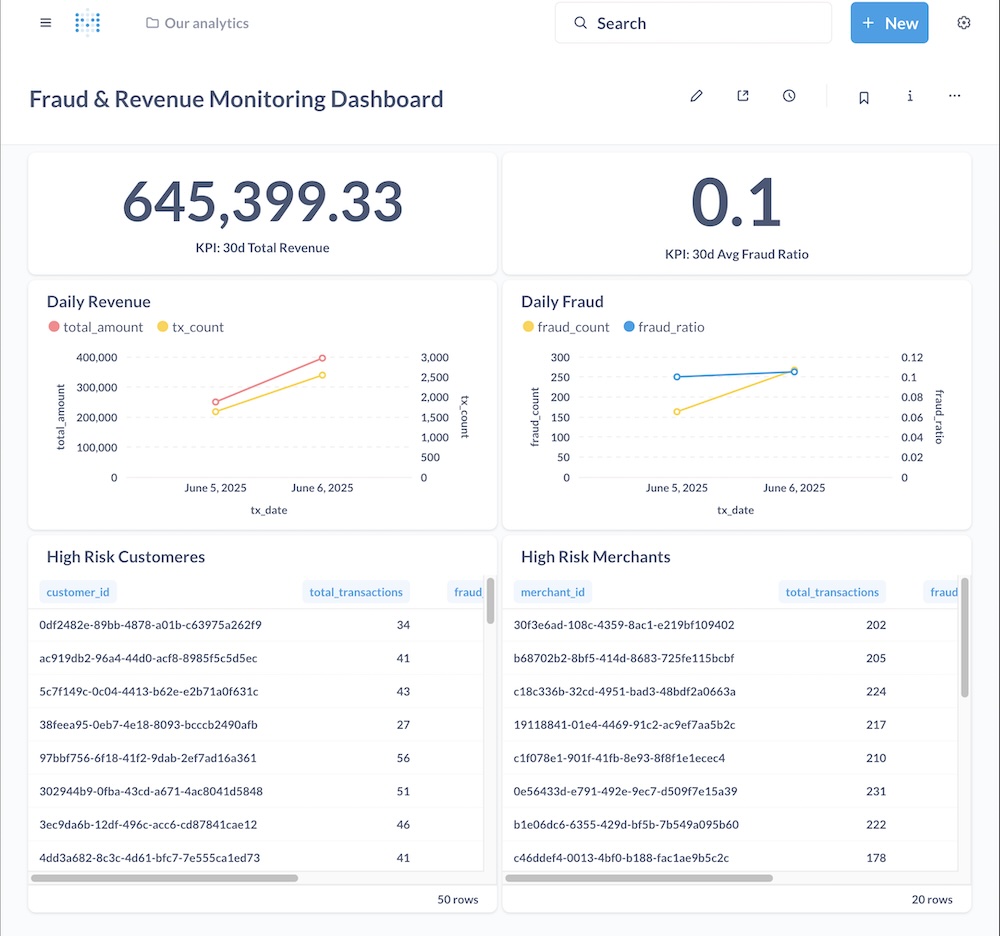
📊 Dashboards
Dashboards were built in Metabase to provide real-time and batch views:
- Daily revenue trends
- Fraud detection overview (suspicious transactions flagged)
- Customer spending distribution
- Merchant-level analytics
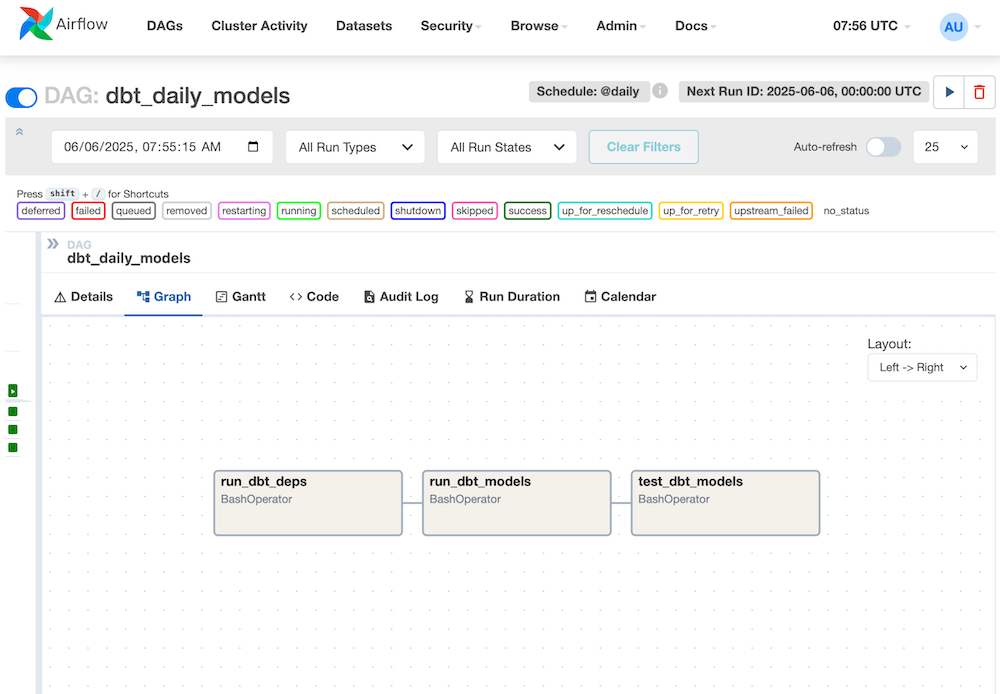
⚙️ Pipeline Orchestration
- Airflow DAGs schedule daily dbt runs and enforce retries
- Modular tasks for ingestion, transformation, and testing
- Fault-tolerant design ensuring late-arriving transactions are captured
🧭 Future Improvements
- Deploy pipeline on Kubernetes for scalability
- Integrate Kafka Connect for CDC simulation
- Extend fraud detection with stateful ML models
- Move warehouse layer to BigQuery or Redshift for cloud scalability
- Add monitoring via Prometheus + Grafana
🧰 Key Skills Demonstrated
- Designing end-to-end data pipelines (streaming + batch)
- Implementing real-time ingestion with Kafka + Spark
- Building OLAP-style schemas with dbt (fact/dim, star schema)
- Orchestration with Airflow and containerized deployment
- Data quality monitoring with dbt tests
- Business-focused dashboarding with Metabase
- Production-oriented mindset: scalable, modular, fault-tolerant
🎯 Takeaway
This project simulates the real-time and batch data integration required in modern fintech and payment platforms. It demonstrates:
- My ability to design and deploy streaming-first architectures
- Hands-on experience with the modern data engineering stack
- A strong focus on data quality, observability, and business outcomes