
Fintech Batch ETL with Redshift Cloud Integration
A production-style batch ETL pipeline for fintech transactions with cloud-ready architecture.
This project demonstrates a cloud-integrated batch ETL pipeline for fintech transaction data, built with Airflow, Spark, dbt, Redshift, and S3.
It simulates how a real financial services company can process, validate, and warehouse millions of daily transactions securely and efficiently.
💡 Project Overview
Financial institutions rely on scalable batch data pipelines to process credit card transactions for analytics such as fraud detection, risk scoring, and customer segmentation.
In this project, I built a production-style batch ETL pipeline that is fully containerized and optimized for cloud integration with AWS.
Key features include:
- End-to-end orchestration with Airflow
- Spark transformations for cleansing, deduplication, and schema evolution
- AWS S3 for Bronze/Silver/Gold data layers
- Redshift for staging, fact, dimension, and marts
- dbt for warehouse modeling and data quality tests
- Great Expectations for validation of curated data
- IAM-based security, encryption, and cost optimizations
🔧 Tech Stack
- Orchestration: Apache Airflow (Dockerized)
- Data Transformation: Apache Spark
- Data Storage: AWS S3 (Bronze, Silver, Gold zones)
- Data Warehouse: AWS Redshift
- Modeling & Testing: dbt
- Data Quality: Great Expectations + dbt tests
- Visualization: Metabase
- Containerization: Docker Compose
- Cloud Security: IAM least privilege, S3 encryption
🏗️ Architecture Summary
Data Flow:
- Bronze (Raw Zone)
- Faker-generated synthetic transactions stored in S3 (JSON/CSV, partitioned by ingest_date).
- Immutable and schema-on-read for auditing.
- Silver (Curated Zone)
- Spark jobs cleanse, deduplicate, enrich, and partition data into Parquet.
- Validated with Great Expectations.
- Gold (Business Zone)
- dbt models in Redshift implementing data marts.
- Used by BI tools like Metabase for customer & merchant analytics.

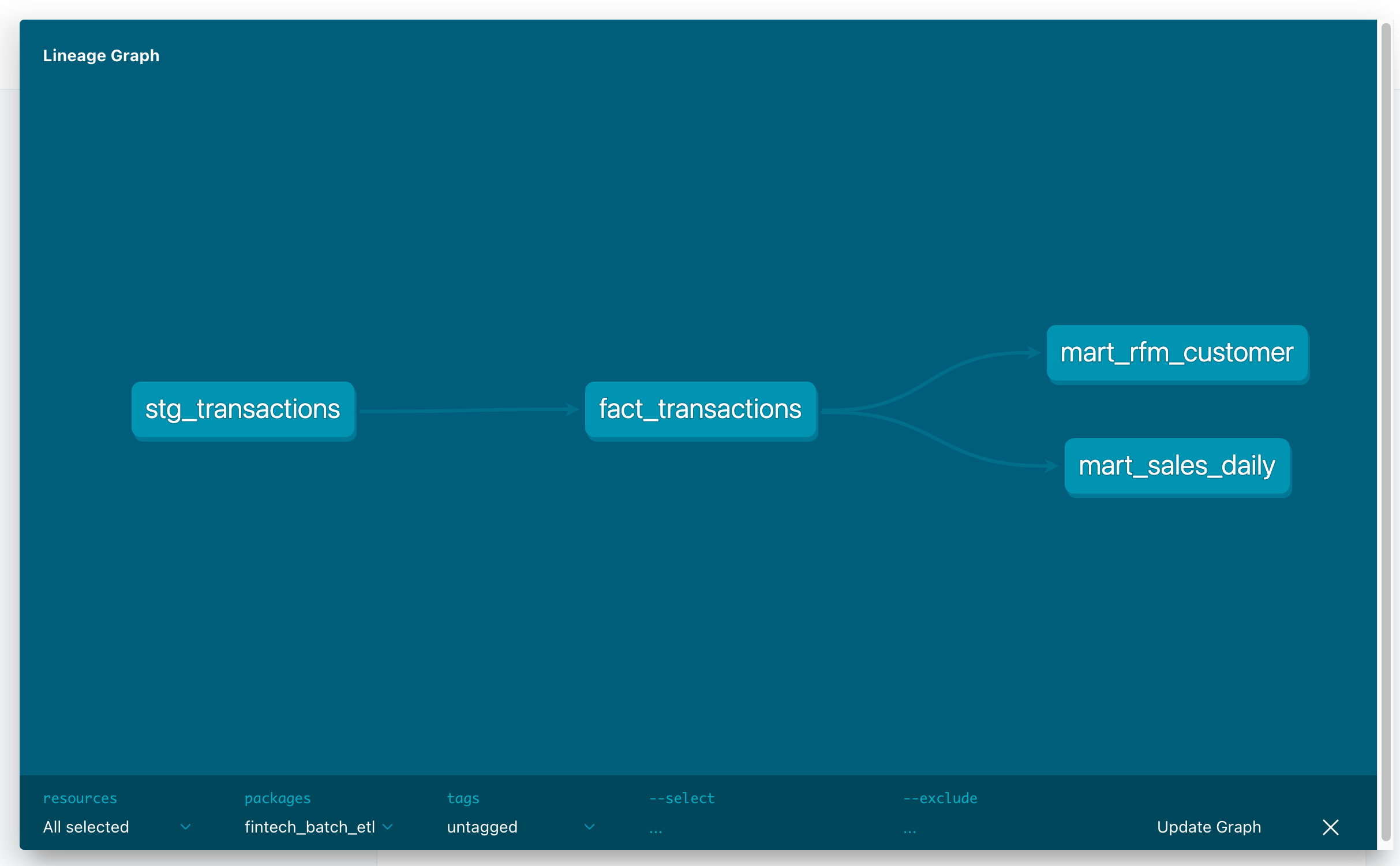
📊 Data Model
- Staging (
stg_*) → 1:1 mapping from Silver zone - Dimensions (
dim_*) → cards, merchants, customers - Facts (
fact_*) → transaction-level events, deduplicated & enriched - Marts (
mart_*) → RFM, LTV, cohort analysis models for BI
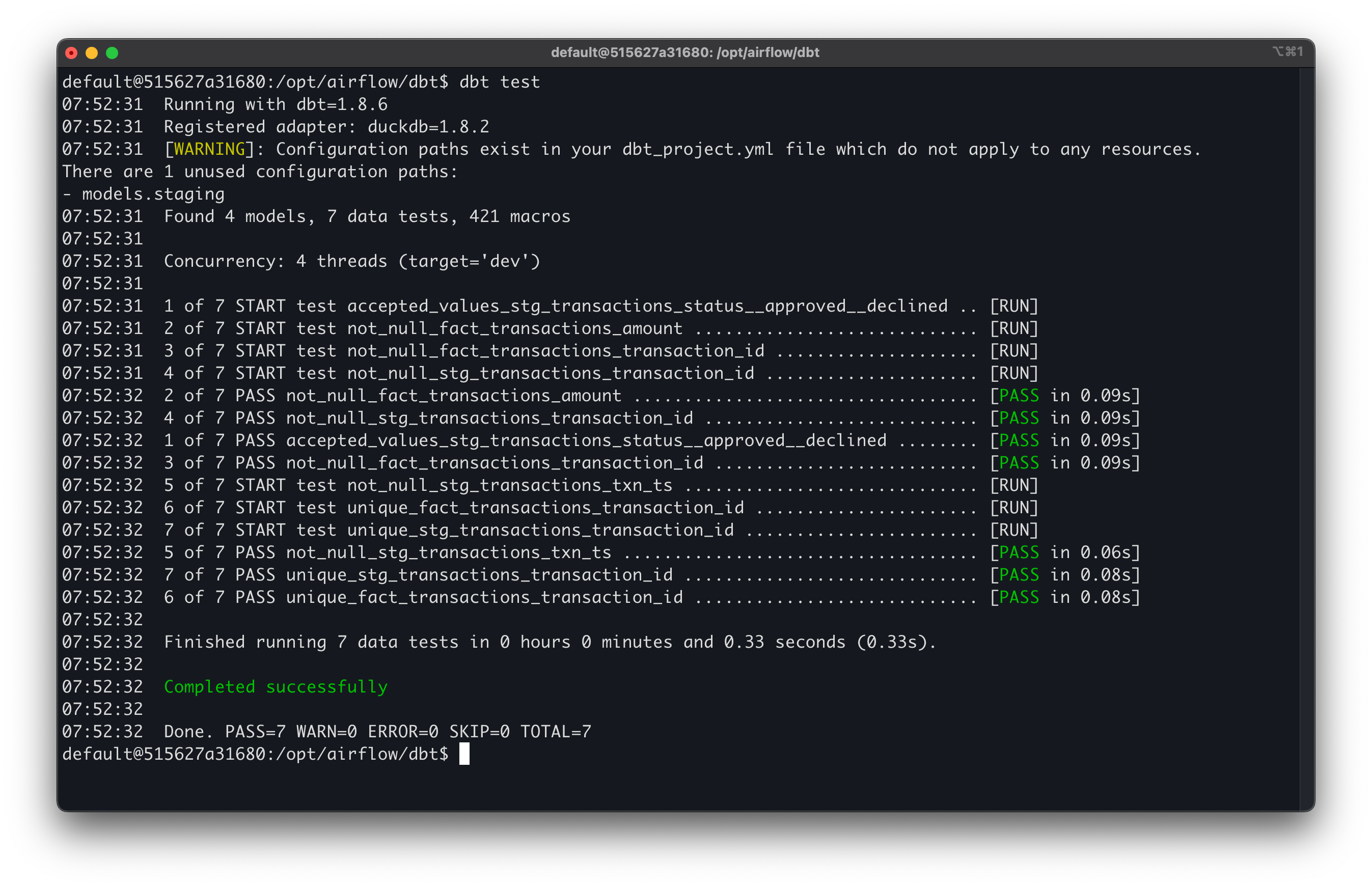
✅ Data Quality Controls
- Great Expectations validation on Silver zone (null checks, enums, ranges)
- dbt tests on Redshift models:
- Uniqueness
- Referential integrity
- Not-null constraints
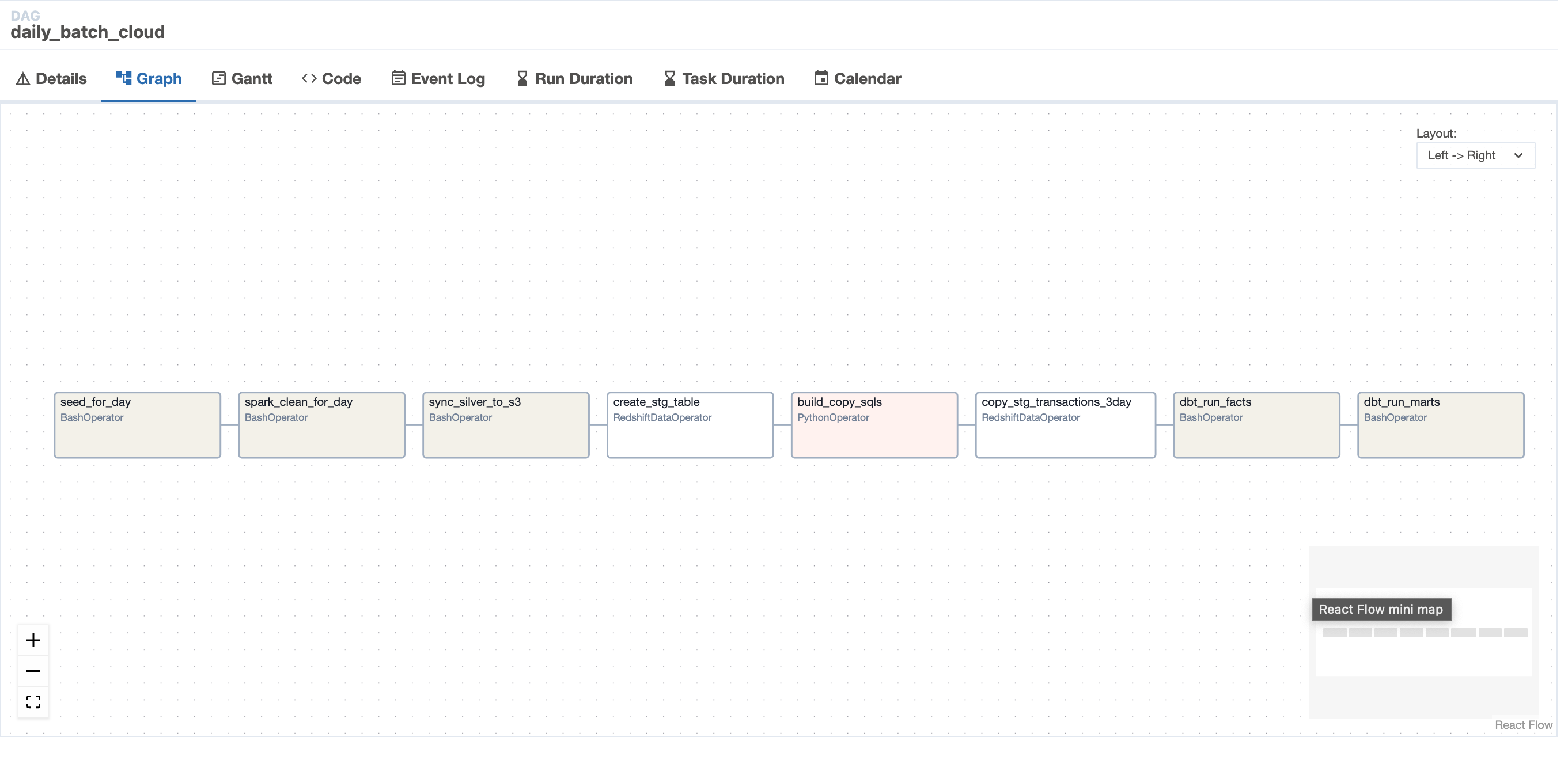
⚙️ Pipeline Orchestration
- Airflow DAGs for ingestion, transformation, validation, and dbt runs
- Backfill & retry handling for late-arriving transactions (up to 2 days)
- Dockerized deployment with all services running locally & cloud-ready
🔐 Cloud Integration Highlights
- AWS S3: Partitioned Parquet storage, encryption at rest
- AWS Redshift: Sort/dist keys for performance, incremental updates for cost control
- IAM Security: Role-based access with least privilege
- Secrets Manager: Secure handling of Redshift & S3 credentials
- Future-Ready: Extendable to Redshift Spectrum, Glue, or Iceberg for hybrid lakehouse
🧰 Key Skills Demonstrated
- Building cloud-native batch ETL pipelines on AWS
- Designing Bronze → Silver → Gold data lakehouse architecture
- dbt-based data modeling and testing in Redshift
- Orchestration with Airflow and Dockerized deployment
- Data quality monitoring with Great Expectations
- Applying cloud security best practices in data engineering
🎯 Takeaway
This project simulates a real-world fintech batch data pipeline that can expand to cloud daily.
It demonstrates:
- My ability to design, build, and operate cloud-integrated data pipelines
- Strong skills in data modeling, validation, and orchestration
- Hands-on experience with AWS services and production-grade engineering