
Retail Card Transaction Data Mart
A fully self-built batch data pipeline simulating real-world retail transaction analytics.
This project showcases my ability to design, build, and operate a full data mart system using modern data engineering tools
💡 Project Overview
When working with retail or fintech transaction data, businesses need robust data pipelines that can clean, transform, validate, and deliver data for reporting and analytics.
In this project, I built a complete OLAP-style data mart pipeline using open-source tools, fully containerized for production-like deployment.
🔧 Tech Stack
- Orchestration: Apache Airflow (Dockerized)
- Data Transformation: dbt (Data Build Tool)
- Data Storage: PostgreSQL (OLAP-style data mart)
- Dashboard & BI: Metabase
- Containerization: Docker Compose
- Cloud Readiness: S3-ready ingestion logic for future extensibility
- Data Quality: dbt tests (accepted range, uniqueness, referential integrity)
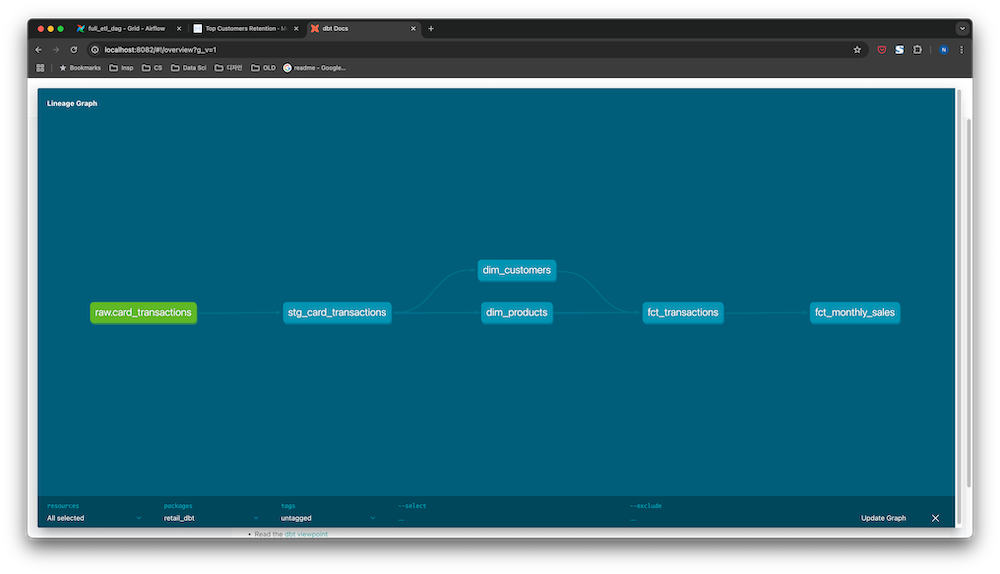
🏗️ Architecture Summary
- Source: UCI Online Retail Dataset (transaction log format)
- ETL Flow:
- Raw ingestion → PostgreSQL
- Staging models → dbt transformations
- Fact and dimension models → Star schema design
- Monthly aggregations → fct_monthly_sales table
- Data quality checks → dbt tests for production readiness
- Orchestration with Airflow:
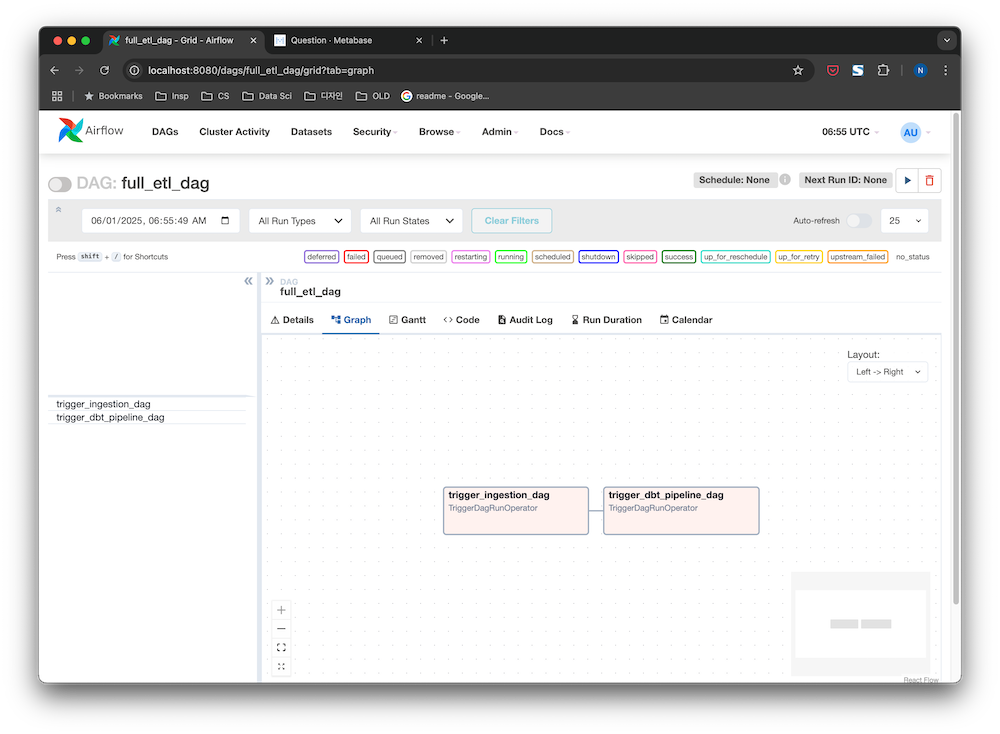
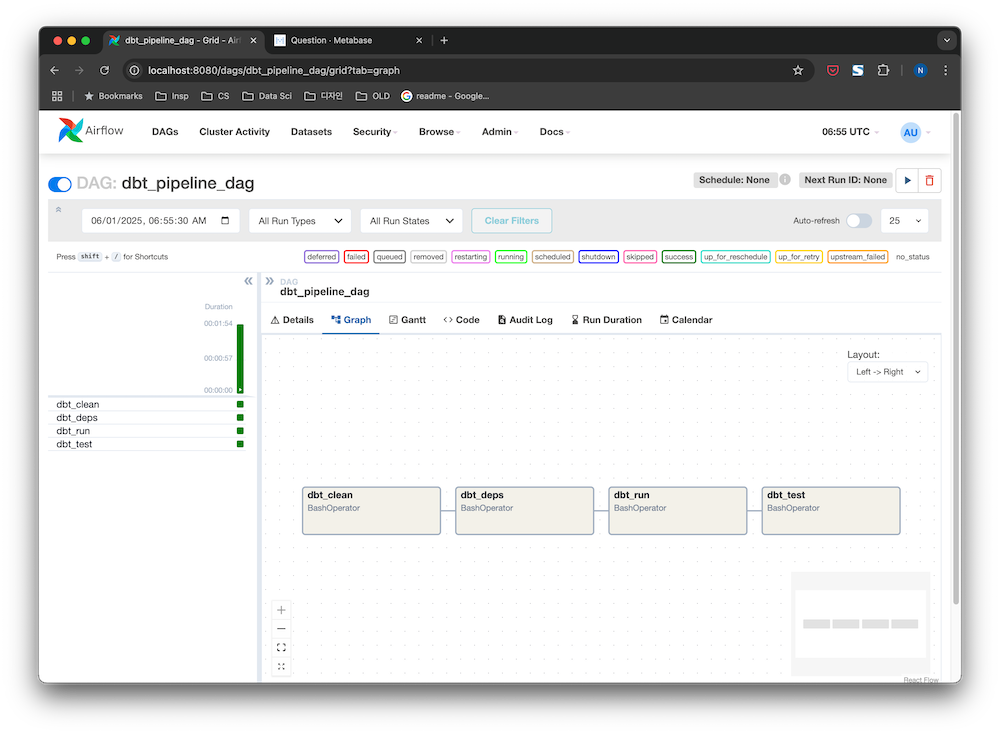
- Modular DAGs:
ingestion_dag,dbt_pipeline_dag,full_etl_dag - Easy to extend and schedule for recurring batch jobs
- Modular DAGs:
📊 Data Mart Design
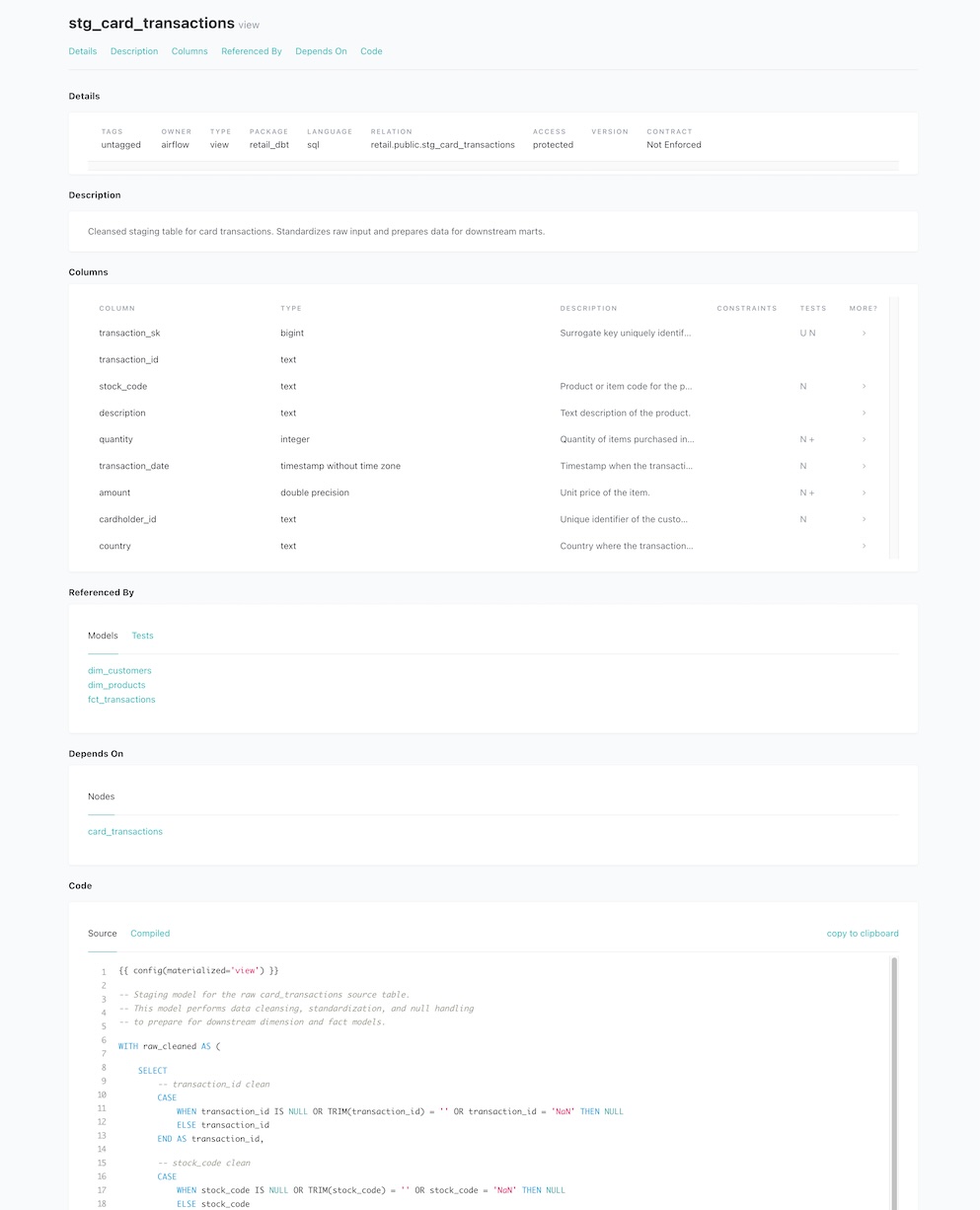
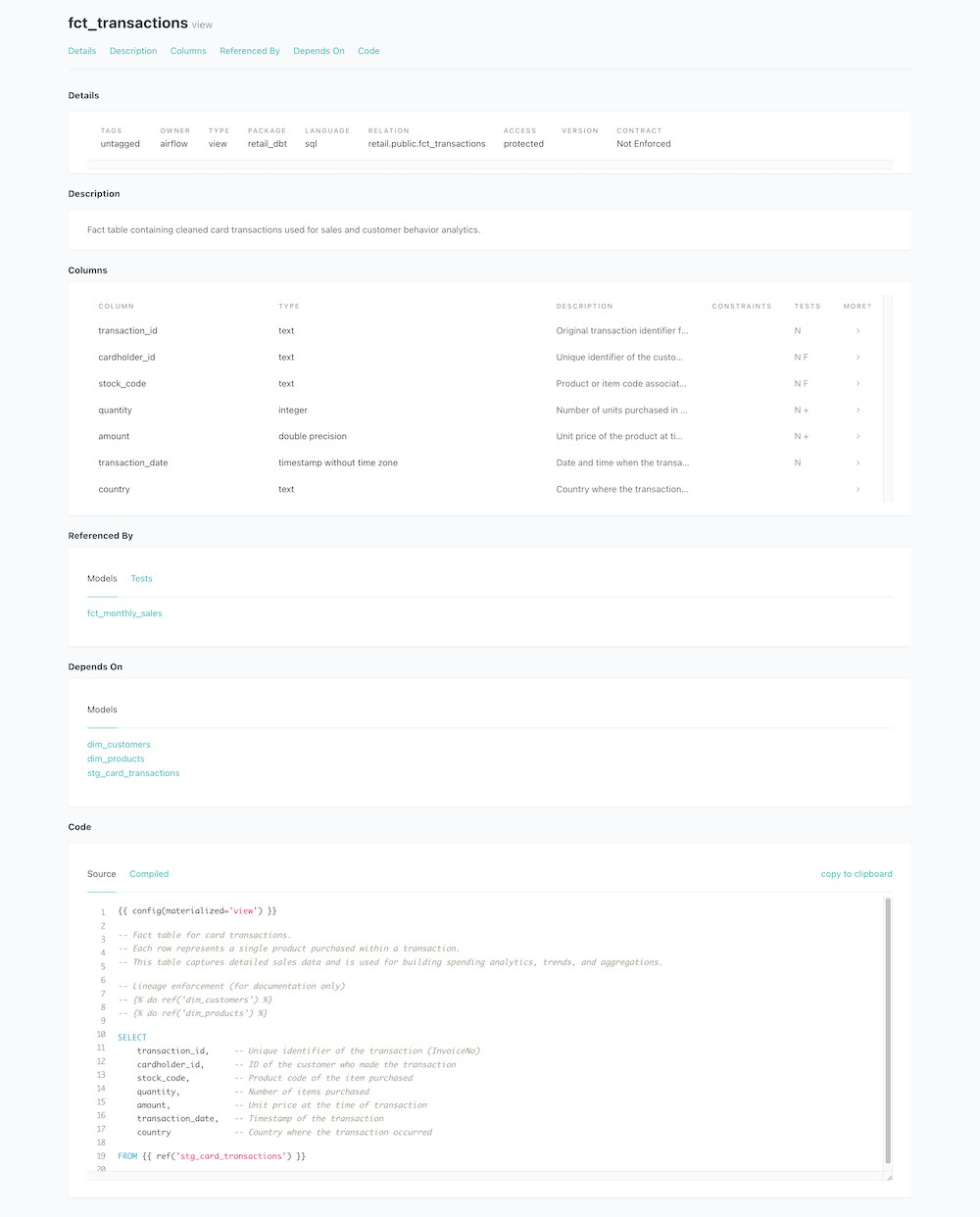
stg_card_transactions: staging layer with data cleansingdim_customers,dim_products: dimension tablesfct_transactions: full transaction-level fact tablefct_monthly_sales: monthly aggregated fact table for BI
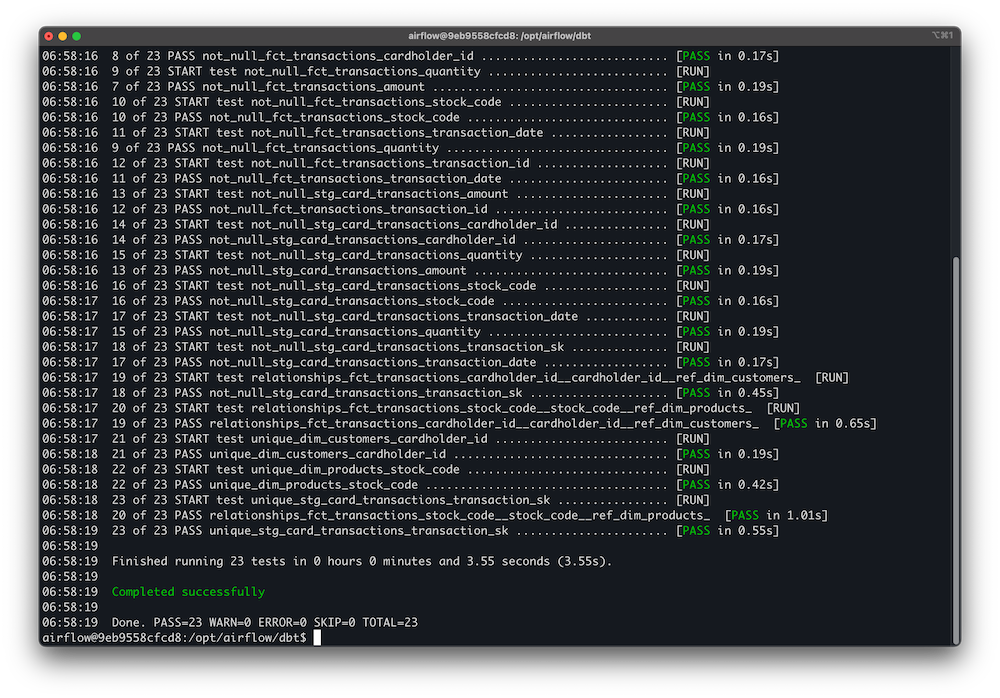
✅ Data Quality Controls
Ensured production-grade integrity with dbt tests:
- Not Null Checks
- Accepted Range Tests (for amount & quantity)
- Unique Keys on surrogate primary keys
- Referential Integrity between fact & dimension models
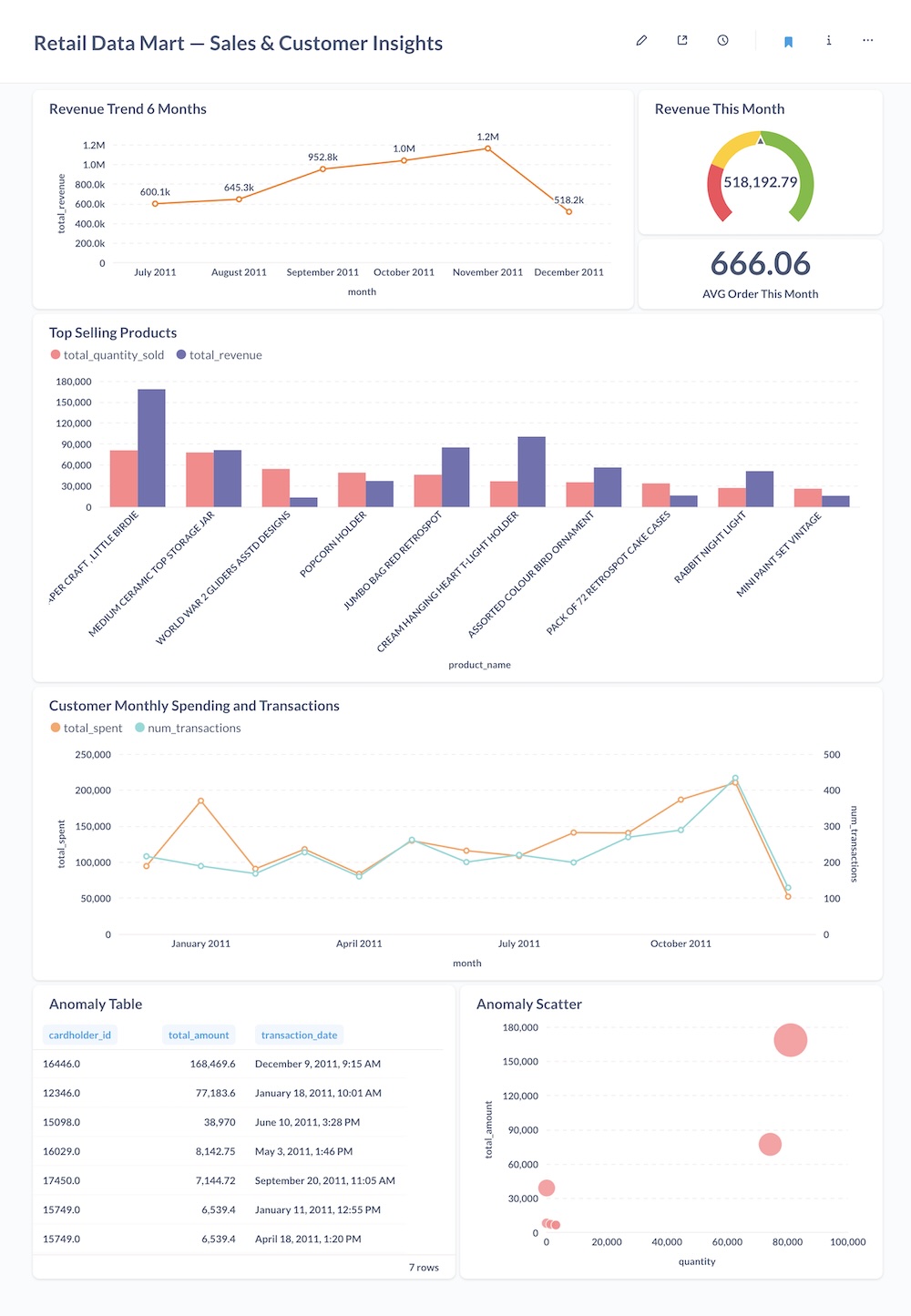
📊 Example Dashboards
Built fully automated dashboards with Metabase:
- Revenue Trends (6-month & current month)
- Average Order Value
- Top Selling Products
- Customer Spending Trends
- Anomaly Detection (suspicious transactions)
⚙️ Pipeline Orchestration
- Dockerized deployment using Docker Compose
- Modular Airflow DAGs for ingestion and transformation
- Fault-tolerant design for batch processing pipelines
🔬 dbt Documentation & Lineage
- dbt docs generated with full model documentation
- Column-level metadata and lineage graphs
🧰 Key Skills Demonstrated
- Full-stack batch data pipeline architecture
- Data mart design using dbt
- Docker-based orchestration of Airflow, dbt, Metabase, PostgreSQL
- Data quality monitoring using dbt tests
- Automated BI dashboards (Metabase)
- Production-grade engineering mindset: modular, scalable, fault-tolerant
🎯 Takeaway
This project simulates real-world batch processing pipelines you’d expect in production data platforms. It demonstrates:
- My ability to own the full pipeline from ingestion to reporting
- My understanding of data validation and observability
- My hands-on experience with modern data stack tools: Airflow, dbt, Docker, Metabase